Diffusion Clicking Head with VLM
Computer use models like Claude can achieve PhD level on academic benchmarks, yet fail miserably to drive an online car using WASD keys only – a task a 5 year old can learn & do very easily.
I’m inspired by progress in robotic VLA models like Helix from Figure and Redwood from 1X for humanoids, and wonder whether it’s possible to attach a System I model (fast, intuitive) to these very smart System II VLMs (slow, reasoning) in order to approach human level reaction time and accuracy on computer use.
The entire digital world is designed for humans using UIs, therefore if we can build models that use them as is we will unlock a new paradigm for agents.
In this project, I’m inspired by GROOT from Nvidia and tried to take that same recipe and apply it for clicking action heads for computers. The diffusion head learns to denoise random coordinates into precise click locations, conditioned on the VLM’s visual understanding and with the VLM frozen during training.
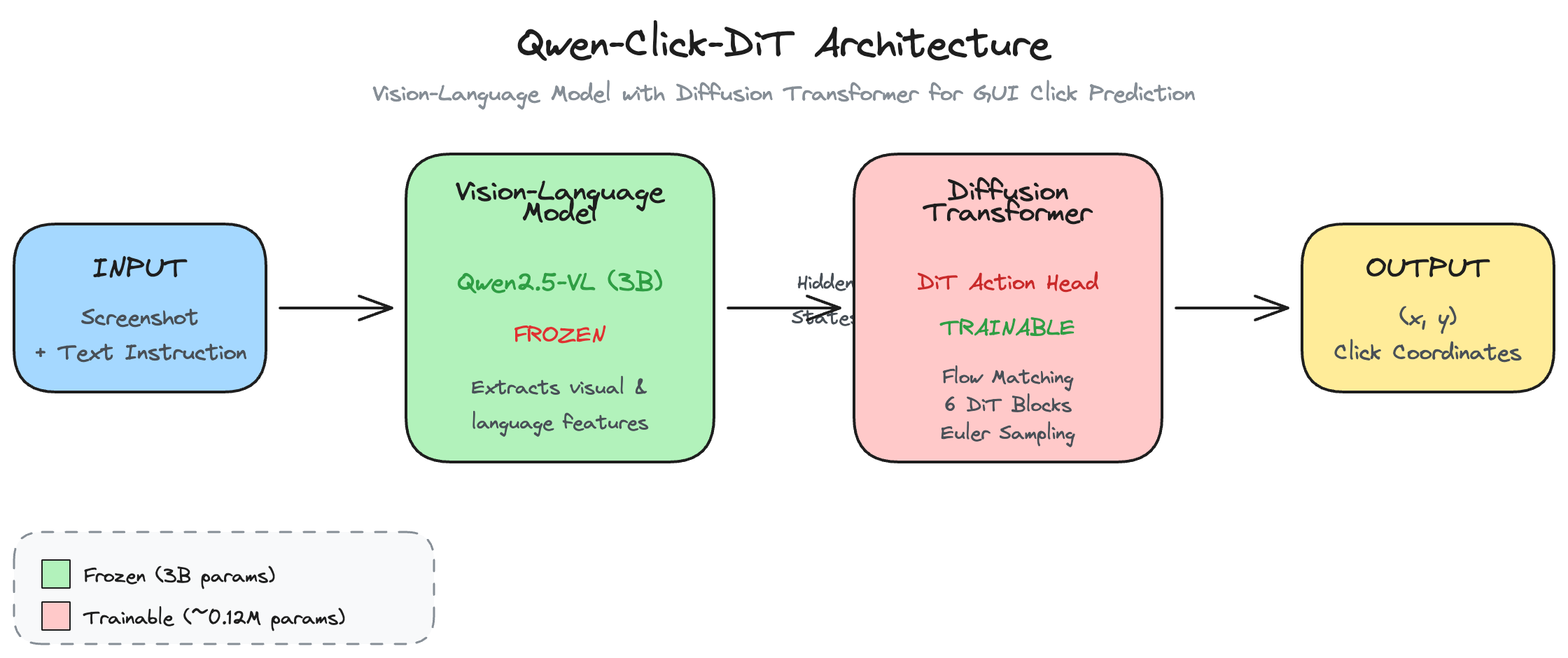
Given my limited resources, I took 20k samples from the Salesforce GUI dataset and trained for 2hrs on an H100. The model was able to learn the data in 3 epochs and produce reasonable clicking coordinates.
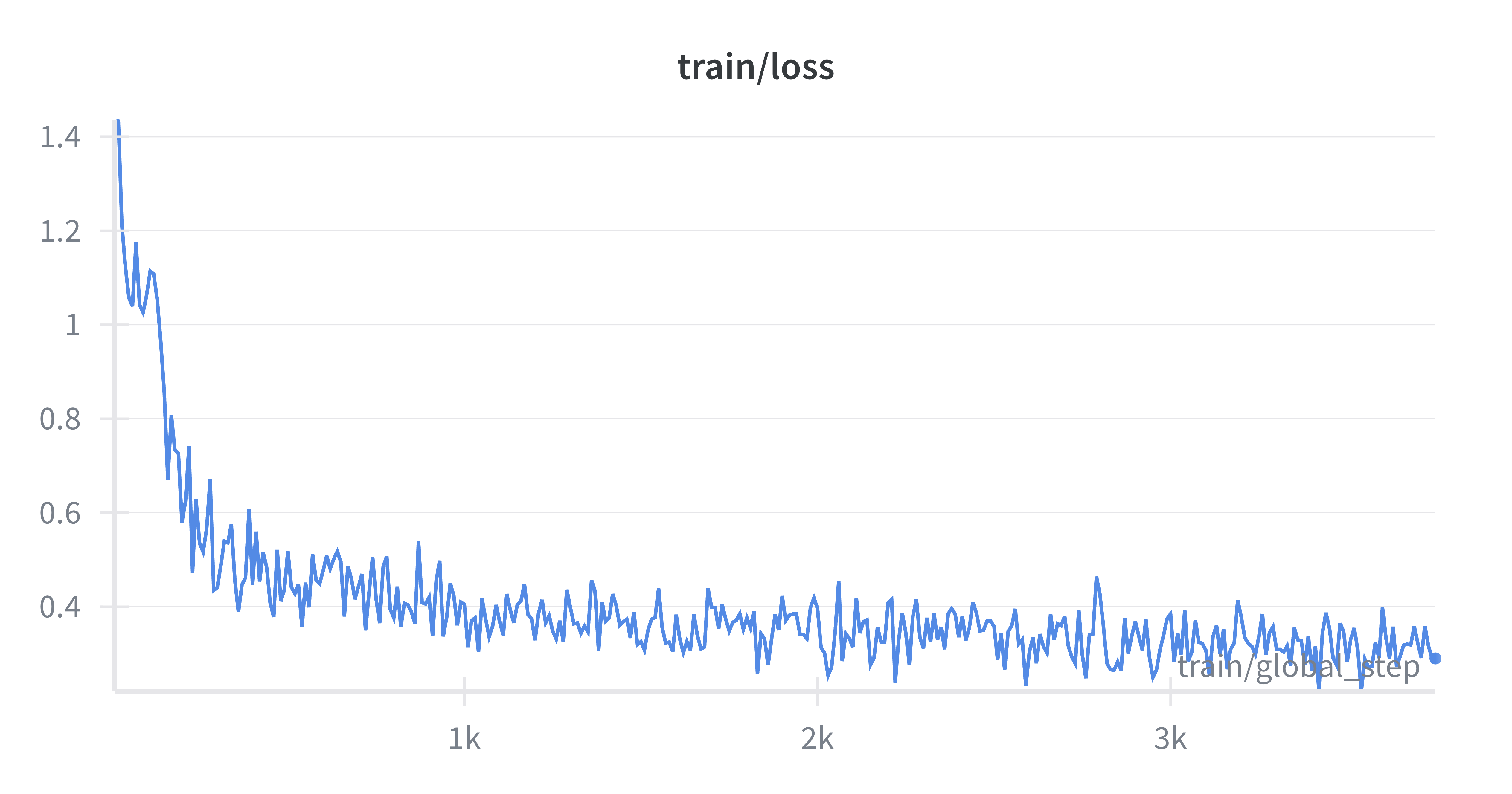
Note that this is with the Qwen2.5-VL-3B model (this is only 0.12M trainable params on top of VLM) and on 20k samples only for one off predictions.
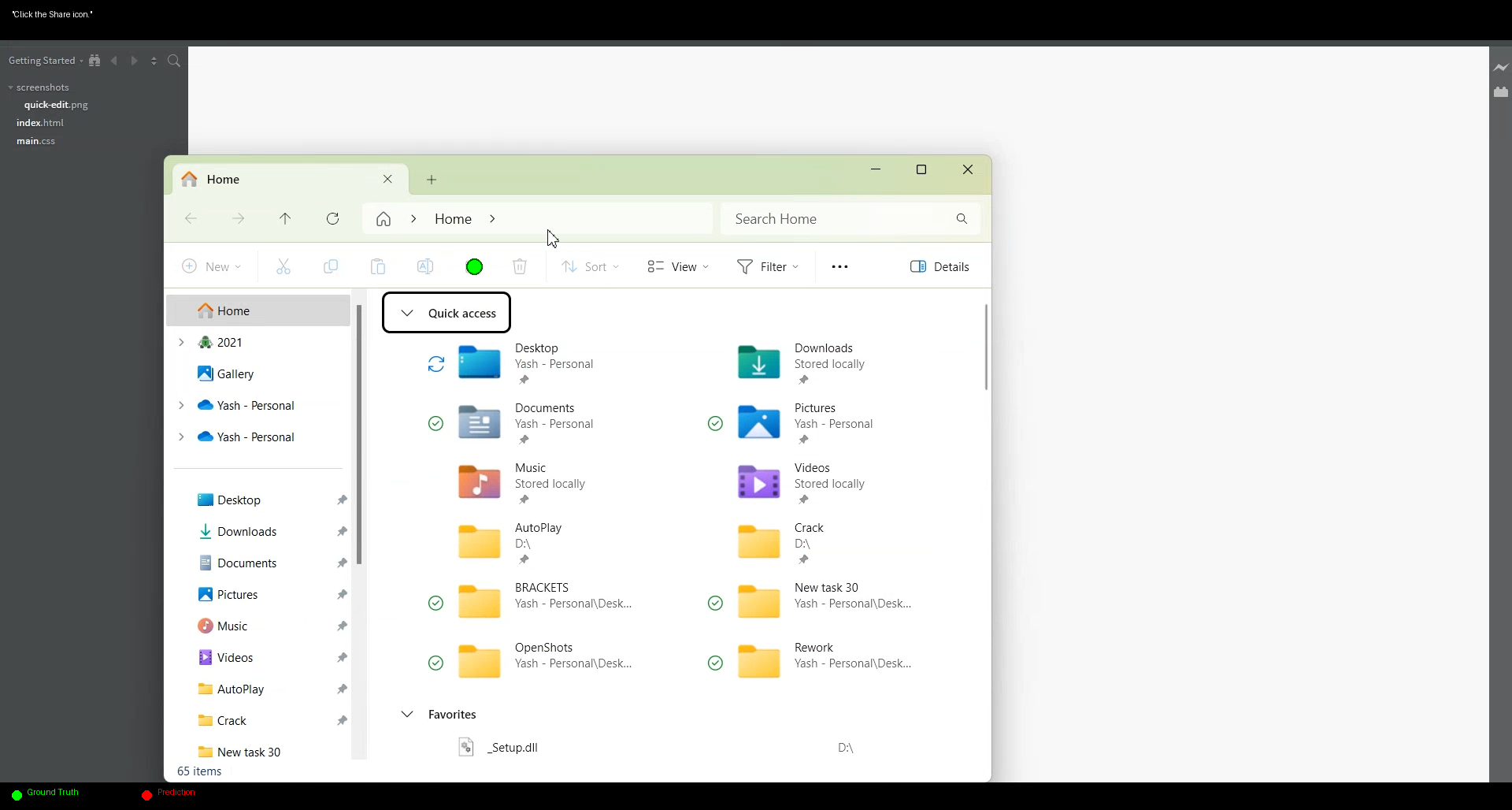
I’m excited about taking this project further by doing full trajectories, and exploring other promising ideas to have a general System I for computer use.